OCR処理はこんな時に大変便利~この道10年の雲紙舎が解説


目次
せっかく紙資料をデータ化したのに……


「PDFの内容をコピペ(コピー&ペースト)したい。」「PDFの中から必要な情報を探したい。」そう思った時に選択や検索をすることできないと困ったことはありませんか。
膨大な量の紙資料をデータ化することにより、保管場所を減らすことができます。また、簡単に職場内で共有できるようになります。しかし、資料をデジタル上で活用できなければ紙資料をデータ化した魅力が半減してしまいます。
WordやExcelのデータのように文字を扱うことのできるPDFとできないPDFは何が違うのでしょうか。
Word、Excel、InDesignなどを使用して文字入力をしたPDFは文字が画像としてではなく、テキストデータとして保存されています。しかし、スキャンして作成したPDFの場合、文字が画像として保存されているため、資料を目で読むことはできますが文字として扱うことができません。
そこで、文字が画像として保存されているPDFにOCR(オーシーアール)という処理をすることによって、コピー&ペーストしたりデータ内検索をしたりできるようにします。
OCRとは何?

OCRとは、Optical Character Recognition/Readerの略称です。日本語では光学的文字認識と言います。
手書きや印刷された文字をイメージスキャナやデジタルカメラで読み取り、その画像の中から文字を見つけ出してデジタルのテキストデータに変換する技術です。
目に見えている画像の文字の上に透明なテキスト文字を埋め込んでいく作業と思っていただくとイメージしやすいかもしれません。
郵便物の郵便番号をスキャンしての自動振り分け、金融機関の振込用紙の読み取り、テストや調査で使われるマークシート読み取りなど、身近な場所でもOCR技術が利用されています。
100%完璧に文字認識をできるわけではないため、必ず誤認識が発生してしまいます。
ソフトがどのようなものが苦手なのか見ていきましょう。
-
 原稿が斜めになっている
原稿が斜めになっている -
 文字間隔が狭い
文字間隔が狭い
(日本語と欧文文字が
混在しているなど) -
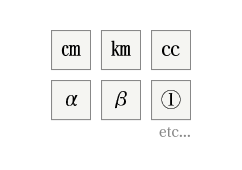 特殊文字(㎝やαなど)
特殊文字(㎝やαなど) -
 カラー文字や文字の擦れ
カラー文字や文字の擦れ -
 横書きと縦書きが
横書きと縦書きが
混在している原稿 -
 アミ掛けされている文字や
アミ掛けされている文字や
背景との色の差があまり
ない文字 -
 手書き文字
手書き文字
しかし、スキャナの設定やスキャン方法を工夫することにより、誤認識発生率をある程度下げることが可能です。
- 300dpi〜600dpiの高い解像度でスキャンする。
- カラー原稿を白黒でスキャンする。
- コントラスト(色の差)を強調する。
- 傾きを補正する。
- 雑誌や辞書など薄い紙や裏写りしやすい原稿は当て紙をして裏写りを軽減する。
このようにしても、カタカナなのか漢字なのかなどをソフトが判別するのは困難です。例えば、「タナカ」という文字が複数回出てくる文章をOCR処理した場合、全てがカタカナで『タナカ』と処理されることは少なく、『タ』が『夕(ゆう)』になったり、『カ』が『力(ちから)』になったりする箇所が出てきてしまいます。
「とりあえずテキストデータがあれば良い。」という場合は、ソフトでOCR処理をするだけで未処理PDFよりも便利にPDFを扱うことができます。
元原稿と一字一句、文字の誤認識のない状態でOCR処理されたPDFが必要な場合、ソフトで処理した後人による目視で1文字1文字検品と修正作業をする必要があります。手作業にかける時間と人数に比例して文字認識率を高くすることができます。
OCR処理済みデータがあればできること
OCR処理済みPDFはあなたの作業効率を上げる手助けになります。
紙資料の情報をテキストデータとして保存しておくことで、情報検索が素早く簡単にできるようになります。
また、WordやExcelなど他の形式に変換することもできますので、一からデータを作り直すよりも手間と時間を節約して情報を再利用することが可能になります。タブ区切りで書き出せば、表計算ソフトで瞬時にグラフ化できます。
紙資料しかなかった時に比べてより効率的に情報を収集、分析、活用ができるようになり、新たな企画に作業時間を回すことができます。
名刺のデータベース化に利用すれば、連絡を取りたい相手をサッと探し出すことができるのはもちろん、名刺に記載されたメールアドレス宛てにすぐメールを送ることもできます。イベントや会合など一度にたくさん名刺をいただいた後の整理にも便利です。
